机器学习的建模步骤以及如何调整模型
基本概念
Machine Learning:Acquiring skill with experience accumulated/computed from data.
🪄Application:
- Speech Recognition
- Image Recognition
- Speaker Recognition
- Machine Translation
建模流程
- 收集训练数据: ${\left(\boldsymbol{x^1}, y^1\right),\left(\boldsymbol{x^2}, y^2\right), \ldots,\left(\boldsymbol{x^N}, y^N\right)}$
其中 $x$ 代表训练数据的输入,即样本,$y$ 代表训练数据的输出,即真值
进行训练
graph LR A("Step 1:<br>function with unknown<br>$$y=f_{\theta}(x)$$") B("Step 2:<br>loss from training data<br>$$L(\boldsymbol{\theta})$$") C("Step 3:<br>optimization<br>$$\boldsymbol{\theta}^*=\arg\ \min _{\boldsymbol{\theta}} L$$") A --> B B --> C其中训练集需要进一步拆分出一个验证集(validation set),其他的数据集用于训练模型,为了更加充分地利用训练集,我们可能会做 k 折交叉验证(k-fold Cross-Validation)
将训练好的模型运用到测试集中,在一般的数据挖掘和预测的平台,例如 Kaggle,一般只提供 public testing set,而对 private testing set 是隐藏起来避免用户训练模型只是恰好在 public testing set 中的效果好,而在未知数据集上表现一般
Testing data: ${\left(\boldsymbol{x^{N+1}}, \hat{y}^{N+1}\right),\left(\boldsymbol{x^{N+2}}, \hat{y}^{N+2}\right), \ldots,\left(\boldsymbol{x}^{N+M}, \hat{y}^{N+M}\right)}$
一般而言,我们规定 $y$ 代表真值(ground truth),而 $\hat{y}$ 代表预测值(predict value)
调整模型
我们可以按照下面的这个流程进行处理
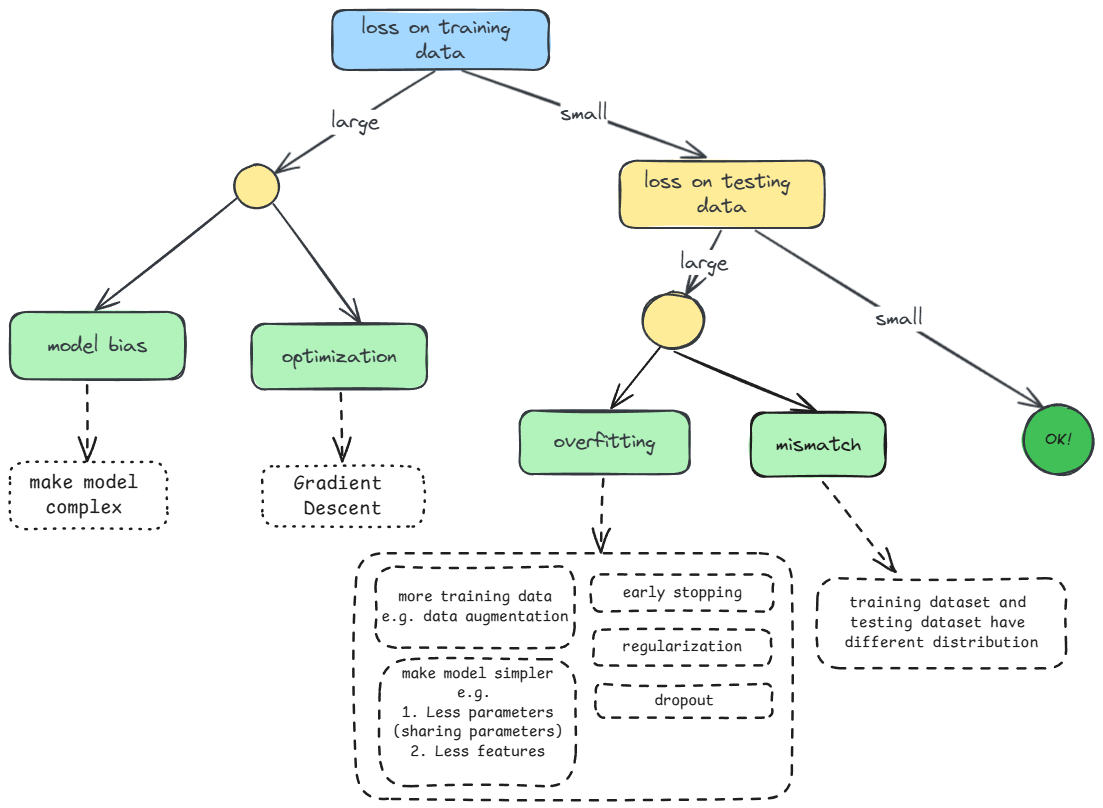
👨🏫对图示进行部分解释和补充
model bias vs optimization issue
- model bias 即模型偏差,是由于 建模过于简单,不够有弹性 导致模型在训练集上训练时,无论怎么改变模型参数,误差仍然很大
- optimization issue 即优化问题,由于在使用 GB 算法存在一个 local minima(局部极小值) 的问题,所以我们可能找到的参数(或参数向量)并不是一个很好的解,导致误差很大
如何判断是 model bias 还是 optimization issue?
多添加几个层数更少的 model 进行对比,如果深层神经网络比浅层神经网络误差更大,那么我们考虑此时深层圣经网络没有参数优化没有做好
overfitting 只有当我们在做测试时才能判断误差是由过拟合产生的